
.webp)
RAG Chatbot in One Week: How We Built Answers People Trust
At Nomtek, we built a retrieval augmented generation assistant for Latarnik (specifically for its MEWA AI chatbot), a civic education platform designed to answer only election-related questions. The rag pipeline connects structured knowledge from verified external knowledge sources with large language models (LLMs) to deliver accurate, transparent information. When the user’s question can’t be answered, the assistant must say so directly.
Why We Needed More Than a Basic Retrieval Augmented Generation Setup
Early versions of the retrieval and generation process worked on paper but failed in testing. The same LLM model produced slightly different results for identical prompts. Hallucinations appeared, retrieved context sometimes included irrelevant or outdated source documents, and minor typos in a user query led to inconsistent outcomes. These problems are common in retrieval augmented generation systems, but they become critical when people rely on the final output for factual, legal, or civic decisions.
Building a Reliable RAG System
We approached this as we would any high-stakes AI system, treating it like traditional software that needs rigorous design, evaluation, and security layers.
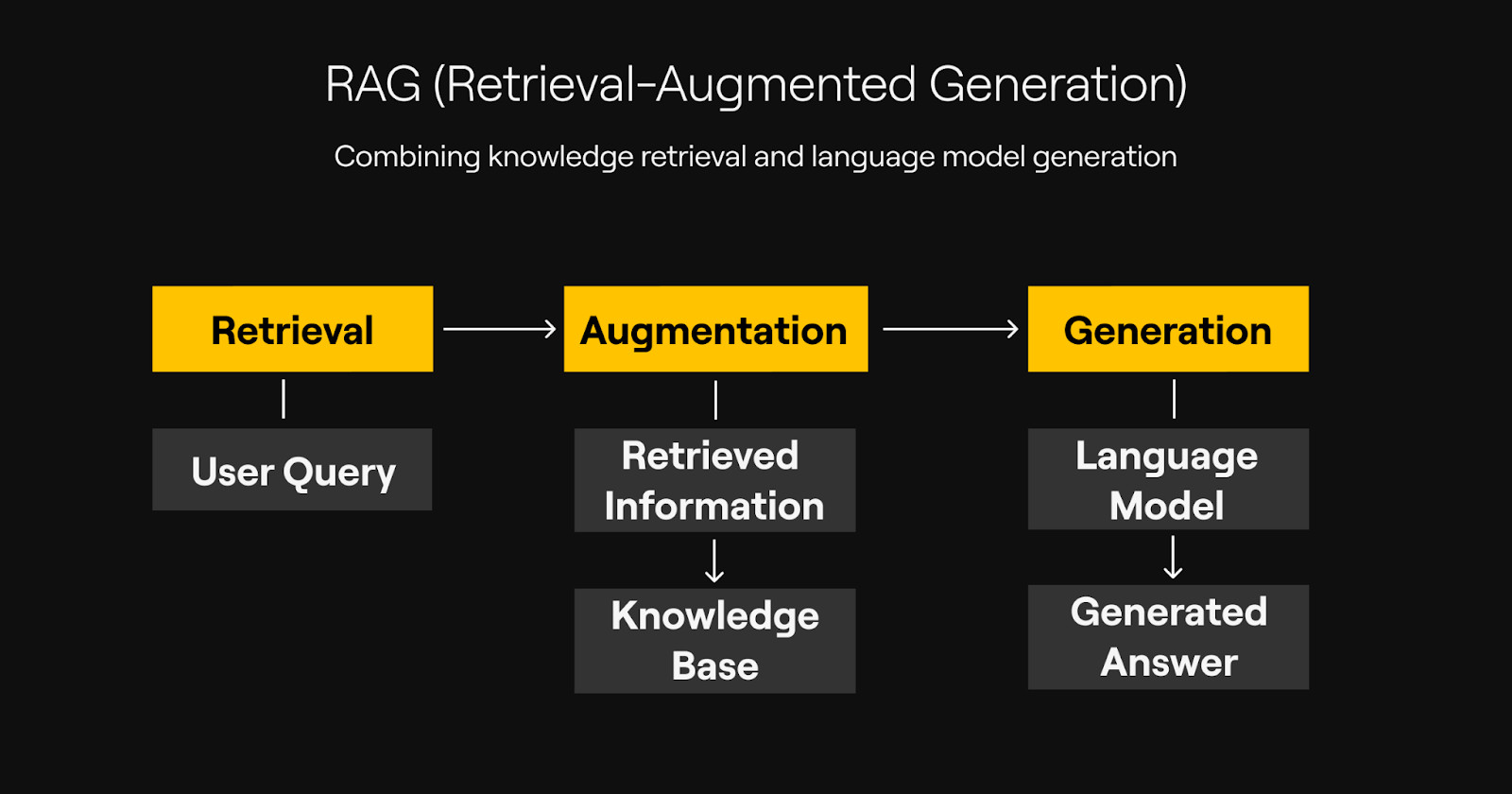
Structuring the RAG Pipeline
Our data ingestion process begins with data loading and data embedding. We pre-process text from PDFs, CSV files, and text files, converting each pdf document into vector form using an embedding model. The vectorized data is stored in a vector database, allowing fast vector search.
When a user asks a question, it’s transformed into an embedding vector. The system compares this vector against stored vectors to find relevant documents. These are the retrieved data that form the provided context for the generation process handled by the LLM model.
This data indexing retrieval approach, built on specialized databases, helps the model ground answers in relevant information instead of inventing facts.
Data Management and Quality
We chunked raw data during ingestion to make document retrieval more efficient. Instead of splitting for training or testing — since no model training occurs in our RAG system — we focused on preparing the content for precise search and retrieval. Each piece of processed data represents a small, semantically coherent part of the source, which helps the system return only the fragments that truly answer the user’s question. This structure keeps the retrieval augmented generation workflow lightweight and improves accuracy without additional model fine-tuning.
The data indexing logic followed a hierarchy: priority first by source credibility, then by document date. This prevented the assistant from citing outdated stored data or low-quality inputs.
Evaluating RAG with Real-World Scenarios
We used rag evaluation frameworks such as RAGAS to track retrieval metrics, custom metrics, and contextual information quality. Faithfulness to the identified data, recall of relevant results, and correctness of the generated output were our key benchmarks.
Our open source framework for testing made it easy to simulate complex queries and verify the consistency of answers across real world applications.
Strengthening Security Through AI Red Teaming
The main security challenge was preventing prompt injection attacks and blocking attempts to provoke hate speech or biased statements that could damage the client’s reputation. Following the OWASP AI Testing Guide, we ran targeted AI red teaming sessions, attacking AI systems with crafted prompts and indirect instructions designed to override content safeguards. These tests strengthened the system’s resistance to manipulation and kept responses aligned with the project’s tone and purpose.
Making the Model Understand Its Role
Defining the assistant’s identity and tone was essential. Inconsistent tone reduces trust, even if the retrieved context is technically correct. We defined the assistant’s voice, limited its scope, and wrote predefined answers for meta questions like “Who built you?” The LLM application thus delivers short, direct, fact-based responses aligned with project goals.
Continuous Evaluation and Regression Testing
We turned one-time experiments into a loop. Every update to the generative language models triggers regression tests with standard and adversarial inputs. These tests confirm that the generated response remains consistent, relevant, and safe.
A monitoring stack — Grafana, Supabase, and analytics — tracks feedback, error patterns, and retrieval metrics. This helped us fine-tune the generation process without sacrificing reliability.
What RAG Reduces (and What It Doesn’t)
A strong RAG system reduces hallucinations, increases factual grounding, and makes generative AI suitable for production. But rag reduces uncertainty, not responsibility: developers must still verify how retrieval augmented generation behaves with new data embedding or vector embeddings. Without clear rules for sourcing and evaluation, even advanced generative language models can mislead users.
A Note on Tooling: Promptfoo
Late in the project, we added Promptfoo, a tool that automated batch prompt testing. It worked as an AI red team helper, letting us replay scenarios and score outputs automatically. That one addition helped us keep the retrieval augmented generation stack consistent as new data and models rolled in.
Lessons from the Field
- Start with data indexing retrieval and tagging. Source governance and formatting quality have a critical impact on how well the RAG system performs. Poorly structured or inconsistent documents lead to weak retrieved context, no matter how strong the model is.
- Define scope, tone, and rules early; contextual information without structure causes drift.
- Run rag evaluation often: retrieval metrics reveal regression before users do.
- Protect sensitive data and stress-test against attacking AI systems.
- Treat feedback loops and analytics as first-class citizens of the rag pipeline.
RAG — For Real-World Applications
This is a reflection of months of iteration, balancing data retrieval, retrieved context, and generation process within a live RAG system. As language models mature and generative AI becomes a standard layer in AI models, grounding them in relevant information and identified data will define the difference between trust and confusion.
Our work on RAG proves that scalable, transparent, and safe retrieval augmented generation isn’t theoretical: it’s already powering real world applications.
FAQ — RAG Pipeline
What does RAG mean in LLM?
RAG stands for retrieval augmented generation (RAG). It’s a method that combines large language models with a document retrieval step, letting the model pull facts from external data instead of relying only on its internal training. This makes generated answers more accurate and grounded in verified sources.
What is the difference between RAG and RAG pipeline?
A RAG pipeline describes the entire retrieval and generation process, starting from the user’s question to the generated output. It includes steps such as data loading, data embedding, and searching high dimensional vectors in a vector database to locate the right context before the model forms a response.
What are some real-world examples of RAG pipelines?
RAG is used in many specific domains, from legal assistants that interpret complex laws to healthcare tools processing domain specific data. In our Latarnik project, the system retrieved relevant information from electoral sources to answer civic questions while keeping language neutral and factual.
What are the benefits of using a RAG pipeline?
RAG improves accuracy and trust. It retrieves relevant documents dynamically, ensuring each answer reflects current and credible content. It also allows organizations to integrate own data from specialized databases, making retrieval augmented generation (RAG) applicable across many industries without retraining large models.
What is red teaming in AI?
Red teaming is a structured method for testing model safety. In RAG systems, it’s often used for AI security, exposing weaknesses such as prompt injection or manipulation attempts. This process helps maintain consistency, protect data privacy, and prevent the model from producing unsafe or off-brand responses.
How does a RAG system process and store data?
In a typical setup, you first load data from various external knowledge sources and run data splitting to create smaller, searchable chunks. These are converted into generated embeddings—mathematical representations that form stored vectors in a vectorized data structure. When a user query arrives, it’s turned into a query vector that’s compared to find the most relevant results.
How does RAG handle query size and data complexity?
Each request must stay within the model’s maximum token length, which defines how much text the system can process at once. Efficient chunking and data embedding help balance context coverage and cost. In real world applications, this ensures that even complex queries return coherent, concise, and accurate answers.

Related articles
Supporting companies in becoming category leaders. We deliver full-cycle solutions for businesses of all sizes.
.webp)
.webp)
.webp)


.webp)
