Can an LLM summarize articles and videos reliably — and cheaply and safely — enough to ship as a consumer app?
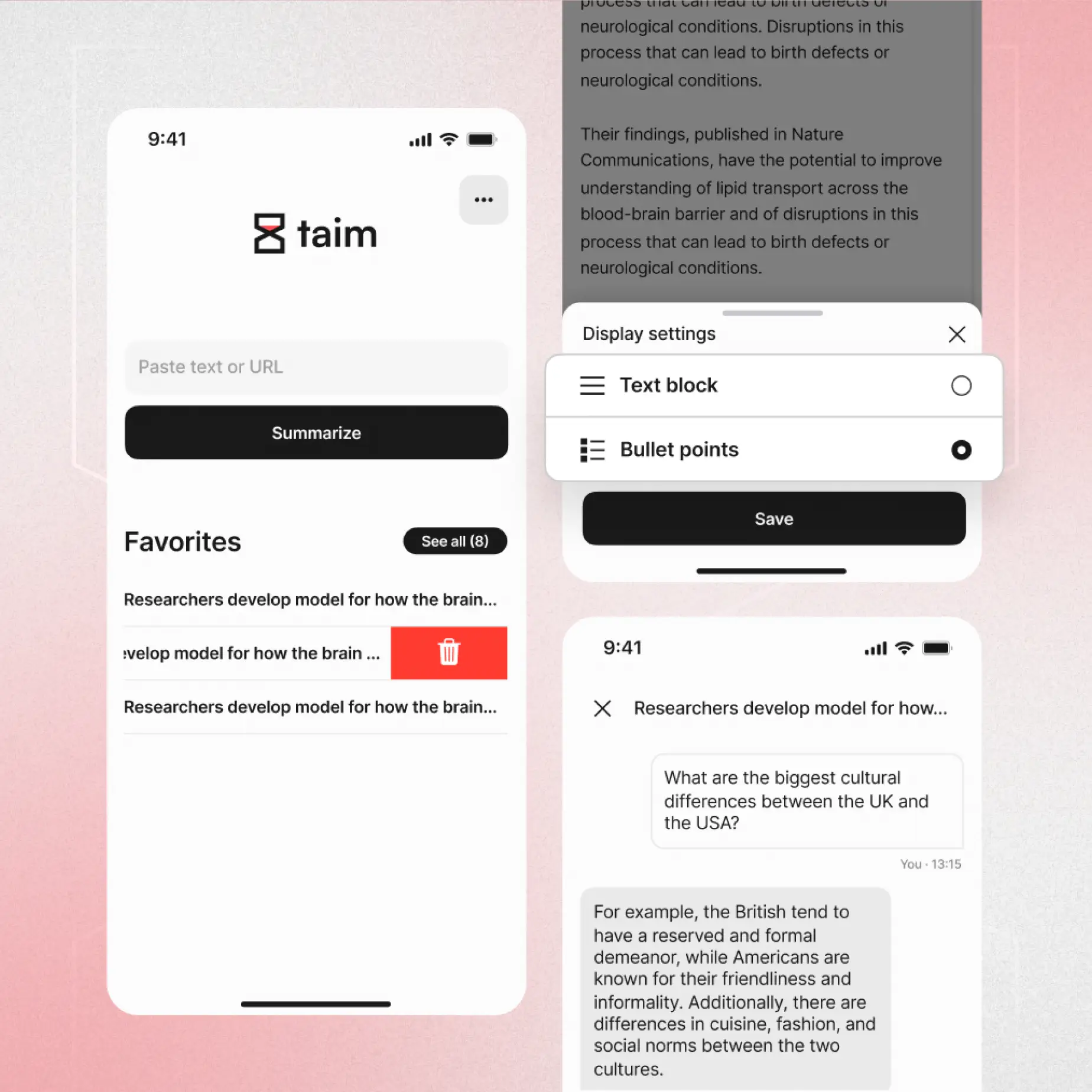



taim is our internal R&D project to explore how large language models perform in everyday user scenarios. The app summarizes articles and YouTube videos into digests in three customizable formats — built to consume and manage information more effectively, with no account required.
taim
2023
We set out to test whether LLM summarization was good enough, cheap enough, and safe enough to underpin a real consumer app.
A cross-platform Flutter app backed by a Fastify (Node.js) service that talks to OpenAI through LangChain, with Helicone for cost monitoring and caching, and a content-moderation step before every summary.
The problem space
The bottleneck in modern information consumption isn't access — it's triage. There's far more worth reading than there is time to read it, so people skim, bookmark, and forget. Summarization is an obvious LLM use case, but shipping it as a product raises three real engineering questions: is the output good enough to trust, can the per-summary cost be controlled at scale, and can a system that ingests arbitrary user-supplied content stay safe? taim was built to answer all three.
customizable summary formats per piece of content
accounts required — privacy-first, no sign-up
content types summarized: long-form articles and YouTube videos
Technology choices
What we evaluated, what we chose, and why.
One codebase for iOS and Android let a small, focused team move fast from prototype through to a polished app without compromising UX.
An efficient, low-overhead web framework to broker complex AI interactions — and the right place to hold API keys, moderation, and caching rather than exposing them on-device.
The standard toolset for building on LLMs; it streamlined the model-interaction layer so we could focus on UX and core functionality.
LLM observability: monitoring prompt behaviour, tracking cost in real time, and caching repeated articles. Critical for keeping a per-summary AI feature cost-effective.
A no-code internal tool to rate the quality of prompts and their summaries, compiling team feedback to find the best-performing prompts — a human-in-the-loop loop for a non-deterministic system.
Rejected. It would have exposed keys, blocked caching, and removed the moderation chokepoint. A backend was non-negotiable.
Rejected at POC stage. Off-the-shelf GPT plus good prompt engineering met the bar far faster and cheaper.
The POC in action
The working thing — capabilities, not a scope list.
Each article or video can be summarized in three customizable lengths/forms, so users pick the depth that fits the moment.
Native share support means you send a link straight from Chrome, YouTube, Safari, or other apps and get a digest back — no copy-paste workflow.
A dedicated moderation step flags inappropriate or unsafe content before summarization, aligned with OpenAI's safety best practices — important when the input is arbitrary user-supplied content.
No account or sign-up required, and summaries work across languages to widen the user base.
Results & takeaways
Honest feasibility findings.
utput quality cleared the bar for a real, shippable product (live on the App Store and Google Play).
Helicone's monitoring and caching of repeated articles kept the per-summary economics in check — the difference between a demo and something you can run at scale.
The same input can yield different outputs, so quality isn't "set and forget." Our Retool human-in-the-loop eval loop was essential — and is itself ongoing work, not a one-time setup.
The same pipeline — plus the reusable prompt-evaluation tooling — maps cleanly onto media and publishing (newsroom and newsletter digests), education (study and revision aids), and enterprise knowledge work such as legal, financial, and research teams that drown in long documents. Each is a vertical where trustworthy, cost-controlled summarization is a product in its own right, not just a feature.
